예외 처리
JPA 표준 예외 처리
JPA 표준 예외들은 javax.persistence.PersistenceException의 자식 클래스다. 그리고 이예외 클래스는 RuntimeException의 자식이다. 따라서 JPA 예외는 모두 언체크 예외다.
- 트랜잭션 롤백을 표시하는 예외 : 트랜잭션 롤백을 표시하는 예외는 심각한 예외이므로 복구해선 안된다. 이 예외가 발생하면 트랜잭션을 강제로 커밋해도 트랜잭션이 커밋되지 않고 javax.persistence.RollbackException 예외가 발생한다.

- 트랜잭션 롤백을 표시하지 않는 예외 : 트랜잭션 롤백을 표시하지 않는 예외는 심각한 예외가 아니다. 따라서 개발자가 트랜잭션을 커밋할지 롤백할지 판단하면 된다.

트랜잭션 롤백 시 주의사항
트랜잭션을 롤백하는 것은 데이터베이스의 반영사항만 롤백하는 것이지 수정한 자바 객체까지 원상태로 복구해주지 않는다. 예를 들어 엔티티를 조회해서 수정하는 중에 문제가 있어 트랜잭션을 롤백하면 데이터베이스의 데이터는 원래대로 복구되지만 객체는 수정된 상태로 영속성 컨텍스트에 남아있다. 따라서 트랜잭션이 롤백된 영속성 컨텍스트를 그대로 사용하는 것은 위험하다. 새로운 영속성 컨텍스트를 생성해서 사용하거나 EntityManager.clear()를 호출해서 영속성 컨텍스트를 초기화한 다음에 사용해야 한다.
엔티티 비교
영속성 컨텍스트 내부에는 엔티티 인스턴스를 보관하기 위한 1차 캐시가 있다. 이 1차 캐시는 영속성 컨텍스트와 생명주기를 같이 한다.
영속성 컨텍스트를 통해 데이터를 저장하거나 조회하면 1차 캐시에 엔티티가 저장된다. 이 1차 캐시 덕분에 변경 감지 기능도 동작하고 이름 그대로 1차 캐시로 사용되어 DB를 통하지 않고 데이터를 바로 조회할 수 있다.
영속성 컨텍스트를 더 정확히 이해하기 위해서는 1차 캐시의 가장 큰 장점인 애플리케이션 수준의 반복 가능한 읽기를 이해해야 한다. 같은 영속성 컨텍스트에서 엔티티를 조회하면 다음 코드와 같이 항상 같은 엔티티 인스턴스를 반환한다.
이것은 단순히 동등성 비교 수준이 아니라 정말 주소값이 같은 인스턴스를 반환한다.

영속성 컨텍스트가 같은 때 엔티티 비교
@Test
@Transactional
public void test03() {
Team team = new Team();
teamService.save(team);
Team saved = teamRepository.findById(team.getId())
.get();
System.out.println(team);
System.out.println(saved);
assertThat(team == saved).isTrue();
}
위 테스트는 트랜잭션 안에서 시작하므로 테스트의 범위와 트랜잭션의 범위가 그림처럼 같다. 따라서 테스트가 진행될 때 항상 같은 트랜잭션 안에서 동작한다. 저장한 Team과 조회한 Team이 같은 영속성 컨텍스트에서 가져오기 때문에 완전 동일한 엔티티이다. 따라서 영속성 컨텍스트가 같으면 엔티티를 비교할 때 다음 3가지 조건을 모두 만족한다.
- 동일성 : ==비교가 같다
- 동등성 : equals()비교가 같다
- 데이터베이스 동등성 : 식별자가 같다
영속성 컨텍스트가 다를 때 엔티티 비교
@Test
// @Transactional
public void test03() {
Team team = new Team();
teamService.save(team);
Team saved = teamRepository.findById(team.getId())
.get();
System.out.println(team);
System.out.println(saved);
assertThat(team == saved).isTrue();
}
이 테스트는 실패한다.

- 테스트 코드에서 memberSerivce.save(team)을 호출해서 팀을 등록하면 서비스 계층에서 트랜잭션이 시작되고 영속성 컨텍스트1이 만들어진다.
- teamRepository에서 team엔티티를 영속화 한다.
- 서비스 계층이 끝날 때 트랜잭션이 커밋되면서 영속성 컨텍스트가 플러시된다. 이때 트랜잭션과 영속성 컨텍스트가 종료된다. 따라서 team엔티티 인스턴스는 준 영속상태가 된다.
- 테스트 코드에서 memberRepository.findById(team.getId())를 호출해 저장한 엔티티를 조회하면 리포지토리 계층에서 새로운 트랜잭션이 시작되면서 새로운 영속성 컨텍스트2가 생성된다.
- 저장된 team을 조회하지만 새로 생성된 영속성 컨텍스트2에는 찾는 team이 없다
- 따라서 데이터베이스에서 team을 찾아온다
- 데이터베이스에서 조회된 team엔티티를 영속성 컨텍스트에 보관하고 반환한다.
- memberRepository.findById(team.getId()) 메소드가 끝나면서 트랜잭션이 종료되고 영속성 컨텍스트2도 종료된다.
team과 saved는 각각 다른 영속성 컨텍스트에서 관리되었기 때문에 둘은 다른 인스턴스이다. 하지만 같은 데이터베이스 로우를 가르키고 있다. 따라서 사실상 같은 엔티티로 보아야 한다.
- 동일성 : ==비교가 실패한다.
- 동등성 : equals()비교가 만족하지만 equals를 구현해야 한다.
- 데이터베이스 동등성 : 식별자가 같다
프록시 심화 주제
영속성 컨텍스트와 프록시
영속성 컨텍스트는 자신이 관리하는 영속 엔티티의 동일성을 보장한다. 그럼 프록시로 조회한 엔티티의 동일성도 보장할까?
@Test
public void test04() {
Team team1 = Team.builder()
.name("team1")
.build();
em.persist(team1);
em.flush();
em.clear();
Team refTeam = em.getReference(Team.class, team1.getId());
Team findTeam = em.find(Team.class, team1.getId());
System.out.println("refMember = " + refTeam.getClass());
System.out.println("findMember = " + findTeam.getClass());
assertThat(refTeam == findTeam).isTrue();
}
먼저 team1을 em.getReference() 메소드를 사용해서 프록시로 조회한 다음 em.find()를 사용해서 조회한다. refTeam은 프록시고 findMember는 원본 엔티티이므로 둘은 서로 다른 인스턴스로 생각할 수 있지만 이렇게 되면 영속성 컨텍스트가 영속 엔티티의 동일성을 보장하지 못하는 문제가 발생한다.
그래서 영속성 컨텍스트는 프록시로 조회된 엔티티에 대해서 같은 엔티티를 찾는 요청이 오면 원본 엔티티가 아닌 처음 조회된 프로깃를 반환한다.
findMember의 타입을 출력한 결과를 보면 뒤에 Proxy가 붙어있는 것을 확인할 수 있다.
@Test
public void test04() {
Team team1 = Team.builder()
.name("team1")
.build();
em.persist(team1);
em.flush();
em.clear();
Team findTeam = em.find(Team.class, team1.getId());
Team refTeam = em.getReference(Team.class, team1.getId());
System.out.println("refMember = " + refTeam.getClass());
System.out.println("findMember = " + findTeam.getClass());
assertThat(refTeam == findTeam).isTrue();
}
반대로 원본 엔티티를 먼저 조회하고 프록시를 조회하면 둘다 원본 엔티티를 얻게 된다. 원본 엔티티를 먼저 조회하면 영속성 컨텍스트는 원본 엔티티를 이미 데이터베이스에서 조회했으므로 프록시를 반환할 이유가 없다. 따라서 em.getReference()를 호출해도 원본 엔티티를 반환한다.
상속관계와 프록시
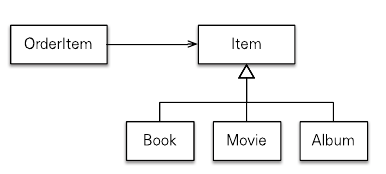
위와 같은 클래스 모델이 있다. 이 모델에서 프록시를 보무 타입으로 조회하면 문제가 발생한다.
@Test
void test01() {
Book book = new Book();
book.setAuthor("kang");
em.persist(book);
em.flush();
em.clear();
Item proxyItem = em.getReference(Item.class, book.getId());
System.out.println("proxyItem = " + proxyItem.getClass());
if (proxyItem instanceof Book) {
System.out.println("proxyItem instanceof Book");
Book book1 = (Book) proxyItem;
System.out.println("책 저자 : " + book1.getAuthor());
}
assertThat(proxyItem.getClass() == Book.class).isFalse();
assertThat(proxyItem instanceof Book).isFalse();
assertThat(proxyItem instanceof Item).isTrue();
}

실행해보면 proxyItem instanceof Book은 false를 반환하고 if문 안에 로직은 수행되지 않는다.
em.getReference() 메소드를 사용해서 Item 엔티티를 프록시로 조회했다. 이때 실제 조회된 엔티티는 Book 이므로 Book 타입을 기반으로 원본 엔티티 인스턴스가 생성된다. 그런데 em.getReference() 메소드에서 Item 엔티티를 대상으로 조회했으므로 프록시인 proxyItem은 Item 타입을 기반으로 만들어진다. 이 프록시 클래스는 원본 엔티티로 Book 엔티티를 참조한다.
출력을 보면 proxyItem이 Book이 아닌 Item 클래스를 기반으로 만들어진 것을 확인할 수 있다. 이런 이유로 proxyItem instanceof Book 연산은 false를 리턴한다. 왜냐하면 프록시인 proxyItem은 Item$HibernateProxy 타입이고 이 타입은 Book과 관계가 없기 대문이다.
따라서 직접 다운 캐스팅을 해도 문제가 발생한다. 예제 코드에서 if문을 제거해보면 ClassCastException이 발생한다. 프록시를 부모 타입으로 조회하면 부모의 타입을 기반으로 프록시가 생성되는 문제가 있다.
- instanceof 연산을 사용할 수 없다.
- 하위 타입으로 다운 캐스팅을 할 수 없다.
이는 주로 다형성을 다루는 도메인 모델에서 나타난다. 예를 들어 Item을 지연로딩으로 설정해서 조회하게 되면 프로깃로 조회되며 위와 같은 문제를 마주한다.
해결 방법
- JPQL로 대상 직접 조회
- 프록시 벗기기
- 기능을 위한 별도의 인터페이스 제공
- 비지터 패턴 사용
성능 최적화
N+1 문제
N+1문제는 Team을 조회했지만 이와 OneToMany로 연관된 엔티티 때문에 추가로 Many쪽 쿼리를 날리는 현상이다. 조회한 Team의 갯수만큼 Many쪽 엔티티 조회 쿼리가 추가로 나간다.
@Test
public void test05() {
TypedQuery<Team> query = em.createQuery("select t from Team t", Team.class);
List<Team> resultList = query.getResultList();
resultList.forEach(System.out::println);
}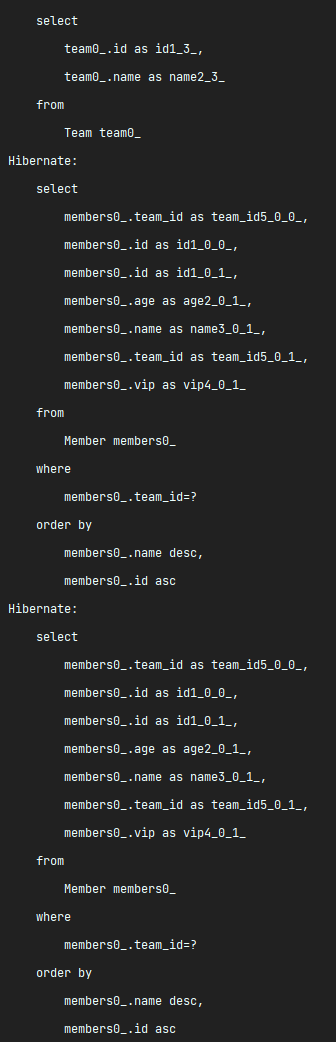
위 예제는 Team을 조회했지만 조회된 Team의 갯수 2만큼 Member를 조회하는 추가 쿼리가 나간 예제이다.
페치 조인 사용
N+1문제를 해결하는 가장 일반적인 방법은 페치 조인을 사용하는 것이다. 페치 조인은 SQL 조인을 사용해서 연관된 엔티티를 함께 조회하므로 N+1 문제가 발생하지 않는다.
@Test
public void test05() {
TypedQuery<Team> query = em.createQuery("select t from Team t join fetch t.members", Team.class);
List<Team> resultList = query.getResultList();
resultList.forEach(System.out::println);
}
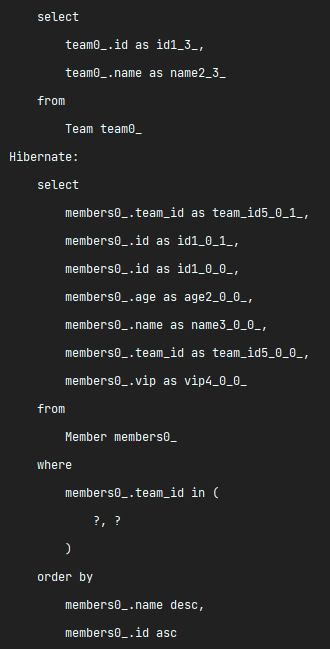
하이버네이트 @BatchSize
하이버네이트가 제공하는 org.hibernate.annotations.BatchSize 어노테이션을 사용하면 연관된 엔티티를 조회할 때 지정한 size만큼 SQL의 IN 절을 사용해서 조회한다.
@OneToMany(mappedBy = "team", fetch = FetchType.EAGER)
@OrderBy("name desc, id asc")
@BatchSize(size = 5)
private List<Member> members = new ArrayList<>();
@Test
public void test05() {
TypedQuery<Team> query = em.createQuery("select t from Team t", Team.class);
List<Team> resultList = query.getResultList();
resultList.forEach(System.out::println);
}
읽기 전용 쿼리의 성능 최적화
엔티티가 여속성 컨텍스트에 관리되면 1차 캐시부터 변경 감지까지 얻을 수 있는 혜택이 많다. 하지만 영속성 컨텍스트는 변경 감지를 위해 스냅샷 인스턴스를 보관하므로 더 많은 메모리를 사용하는 단점이 있다. 예를 들어 100건의 구매 내용을 출력하는 단순한 조회 화면이 있다고 가정해보자. 그리고 조회한 엔티티를 다시 조회할 일도 없고 수정할 일도 없이 딱 한번만 읽어서 화면에 출력하면 된다. 이때는 읽기전용으로 엔티티를 조회하면 메모리 사용량을 최적화할 수 있다.
select o from Order o- 스칼라 타입으로 조회
select o.id, o.name, o.price from Order o- 읽기 전용 쿼리 힌트 사용
query.setHint("org.hibernate.readOnly", true);- 읽기 전용 트랜잭션 사용
@Transactional(readOnly = true)- 트랜잭션 밖에서 읽기 : 트랜잭션 없이 엔티티 조회
'spring > jpa' 카테고리의 다른 글
| 자바 ORM 표준 JPA 프로그래밍 - 16장 트랜잭션과 락, 2차 캐시 (0) | 2021.09.05 |
|---|---|
| 자바 ORM 표준 JPA 프로그래밍 - 14장 컬렉션과 부가 기능 (0) | 2021.08.28 |
| 자바 ORM 표준 JPA 프로그래밍 - 13장 웹 애플리케이션과 영속성 관리 (0) | 2021.08.21 |
| 자바 ORM 표준 JPA 프로그래밍 - 12장 스프링 데이터 JPA (0) | 2021.08.17 |
| 자바 ORM 표준 JPA 프로그래밍 - 10장 객체지향 쿼리 언어 (0) | 2021.07.24 |




댓글